O step Text File Input é utilizado para ler diversos tipos de arquivos texto. O formato mais comum entre eles é o Comma Separated Values (CSV). Caso o arquivo texto tenha qualquer outra extensão, será necessário que o mesmo possua campos de tamanho fixo.
Este componente, assim como o Excel Input, permite que o usuário selecione uma lista de arquivos a serem lidos, ou uma lista de diretórios de onde serão lidos os arquivos, podendo ou não obedecer uma expressão regular. Além disso, o step também poderá receber diretórios ou nomes de arquivos provenientes de steps anteriores, seja por variável, seja por um campo do fluxo, permitindo desta forma que o manuseio dos arquivos seja ainda mais genérico.
Veremos a seguir as opções específicas, ou seja, o diferencial deste componente em relação aos outros steps de Input.

Filetype – o usuário poderá definir entre um arquivo do tipo CSV ou um arquivo de tamanho fixo;
Separator – caso o arquivo seja do tipo CSV, é provável que você defina o separador dos campos. Normalmente a vírgula ou o ponto-e-vírgula são mais utilizados;
Enclosure – caso os campos estejam dentro de um par de caracteres (parênteses ou aspas duplas por exemplo), o caractere deve ser definido aqui;
Escape – define o caractere que irá ignorar o caractere definido como separator, caso este seja necessário dentro do texto.
Ex: Se o separator for uma aspas simples, e uma coluna tiver o texto ‘Gota d´água’, será necessário que o arquivo CSV venha com o texto ‘Gota d\´água’ para que o componente entenda este texto como um campo só ao invés de dois. Neste caso, a barra serve como Escape;
Header – define se haverá um cabeçalho e quantas linhas correspondem a este cabeçalho;
Footer – segue a mesma regra do Header também para o rodapé;
No empty rows – impede que as linhas vazias sejam enviadas para o fluxo;
Include filename in output – define se o nome do arquivo também será enviado ao fluxo;
Filename field name – define o nome do campo que levará o nome do arquivo pelo fluxo;
Rownum in output – define se o número da linha no arquivo será enviada ao fluxo;
Row number field name – define o nome do campo que levará o número da linha;
Rownum by file? – define se o número das linhas será reiniciado a cada arquivo lido;
Format – formato do arquivo. Pode ser DOS, UNIX ou mixed;
Encoding – especifica o encoding que será utilizado;
Limit – Especifica o número de linhas que serão lidas por arquivo. 0 (zero) significa a leitura de todas as linhas.
Na aba Fields, veremos mais algumas especificidades do componente. Caso tenhamos escolhido o tipo de arquivo CSV na aba Content, basta clicar no botão “Obtém Campos” e, automaticamente, os campos identificados de acordo com o cabeçalho (Header) e divididos pelo caractere definido como Separator serão exibidos.

Caso o tipo de arquivo definido na aba Content seja Fixed, ao clicarmos no botão “Obtém Campos”, visualizaremos a seguinte tela:
Ao clicarmos em qualquer ponto da visualização do arquivo, definiremos a quantidade de caracteres e/ou espaços que formarão os campos. A seta vermelha indica o limite do campo. Para adicionar uma seta, basta clicar no ponto desejado. Para retirar a limitação, basta clicar novamente sobre a seta.
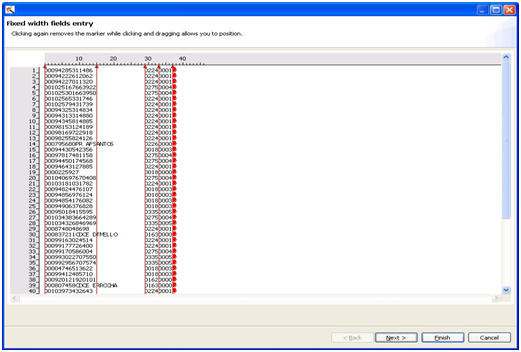
Ao seguirmos pelo botão “Next”, definiremos o nome de cada campo que acabamos de definir. Perceba que na parte direita da janela visualizaremos os dados do intervalo de espaço que definimos anteriormente.

Olá, Luciano, tudo bem?
ResponderExcluirVocê saberia me dizer se há alguma forma de ler um arquivo de texto e fazer com que o PDI leia a partir de uma determinada linha? Por exemplo: tenho um arquivo que possui cabeçalhos com informações sobre aqueles dados. A tabela de dados começa efetivamente a partir da linha 7, sendo a 7 o nome das colunas. Tem como setar isso no PDI sem ter que retirar o cabeçalho antes? Obrigado!
Abraços!
Olá Wisley,
ResponderExcluirComo você já sabe exatamente o número da linha que precisa, você pode fazer o seguinte. Após extrair as linhas do arquivo texto, adicione um step "Add Sequence", começando do número 1 e incrementando de 1 em 1 e, em seguida, coloque um step "Filter Rows". Desta forma, você pode controlar pra que apenas as linhas cujo número seja maior ou igual a 7 passem adiante.
Abraço e boa sorte!
Se eu gero uma stage a partir de um csv muito grande, como eu faço a validação dos dados? Provar que os dados estão batendo; pois em arquivos excel eu faço fórmulas de colunas e verifico, agora em csv não sei
ResponderExcluirLuciano, tenho um arquivo separado por "|" e tenho uma linha iniciando por "|0000|"recorrente, essa linha vai ser uma das minhas dimensões, como faço para que o Kettle identifique isso? Obg.
ResponderExcluirLuciano, bom dia!
ResponderExcluirComo faço para separar num arquivo da seguintes forma:
linha que começa com 0-Tem os dados da empresa
linha que começa com 1-Tem os dados de nota fiscal
linha que começa com 2-Tem os dados de endereço da empresa
linha que começa com 3-Tem os dados de bilhetagem
linha que começa com 4-Tem os dados de chamadas
linha que começa com 5-Tem os dados de consumo
Sendo que as linhas 3, 4 e 5 são referentes aos dados da linha 1 e 2.
E toda vez que a linha 1 é renovada, as linhas 2, 3, 4 e 5 são referentes a essa linha.
Não faço ideia como fazer.
Esse é o arquivo da FEBRABAN quanto aos gastos com telefonia V30R.
Este comentário foi removido pelo autor.
ResponderExcluirTenho um arquivo com 1,5 milhões de linhas e queria filtrar pelo numero de linhas de cada ano. Não quero usar o step filter, pois este faz a leitura completa das 1,5 linhas do arquivo para depois filtrar o ano específico. Como já filtrar na leitura do arqueiro somente as linhas do ano que desejo? Posso passar parâmetro? PS: o componente filter além de não impedir a leitura total do arquivo ele não permite parâmetro
ResponderExcluir